
The machine: 2xIntel(R) Xeon(R) Gold 6326 CPU @ 2.90GHz, 2xNVIDIA A100 80GB PCIe, no p2p GPU access.
AMD CPU server: 2xAMD EPYC 9754
Periodic shock box
Test solver. 2nd order + Barth limiter + SSPRK3, CFL=0.5
Number of cells iterations per second, CI/s
Using 1024^2 cells.
| Machine | Performance (CI/s) | Power estimated ( by software) (W) | Efficiency (MCI/kJ) |
|---|---|---|---|
| 1 A100 | 7.5M | 120 (GPU) + 175 (CPU Package) + 25 (RAM) = 320 | 23.4 MCI/kJ |
| 2 A100 | 14.7M | 120 (GPU) * 2 + 175 (CPU Package) + 25 (RAM) = 440 | 33.4 MCI/kJ |
| 32 CPU cores | 4.2M | 360 (CPU Package) + 45 (RAM) = 405 | 10.37 MCI/kJ |
Using 16 OMP thread x 2 ranks performs nearly the same as (slightly worse than) 32 ranks.
GPU python profile results
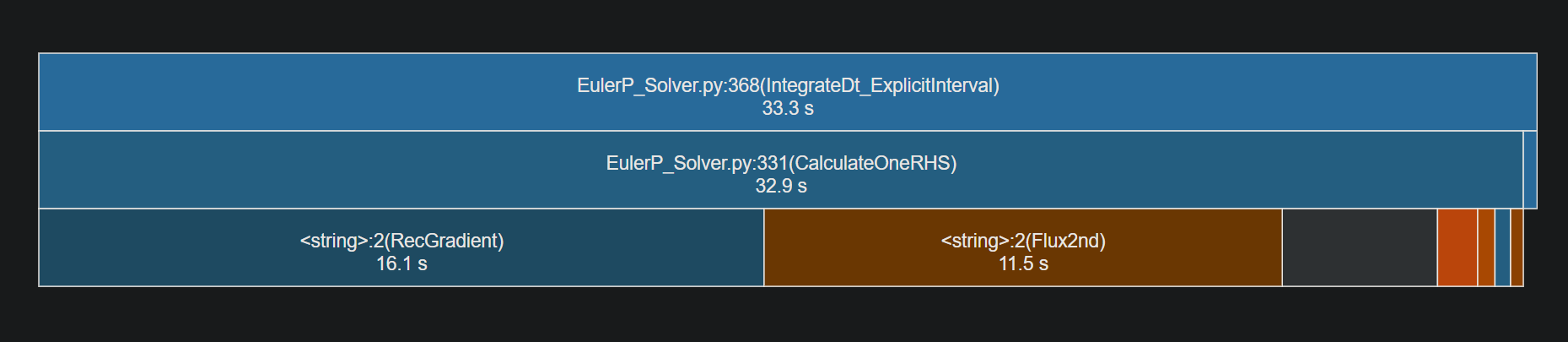
CPU python profile results

NSYS results
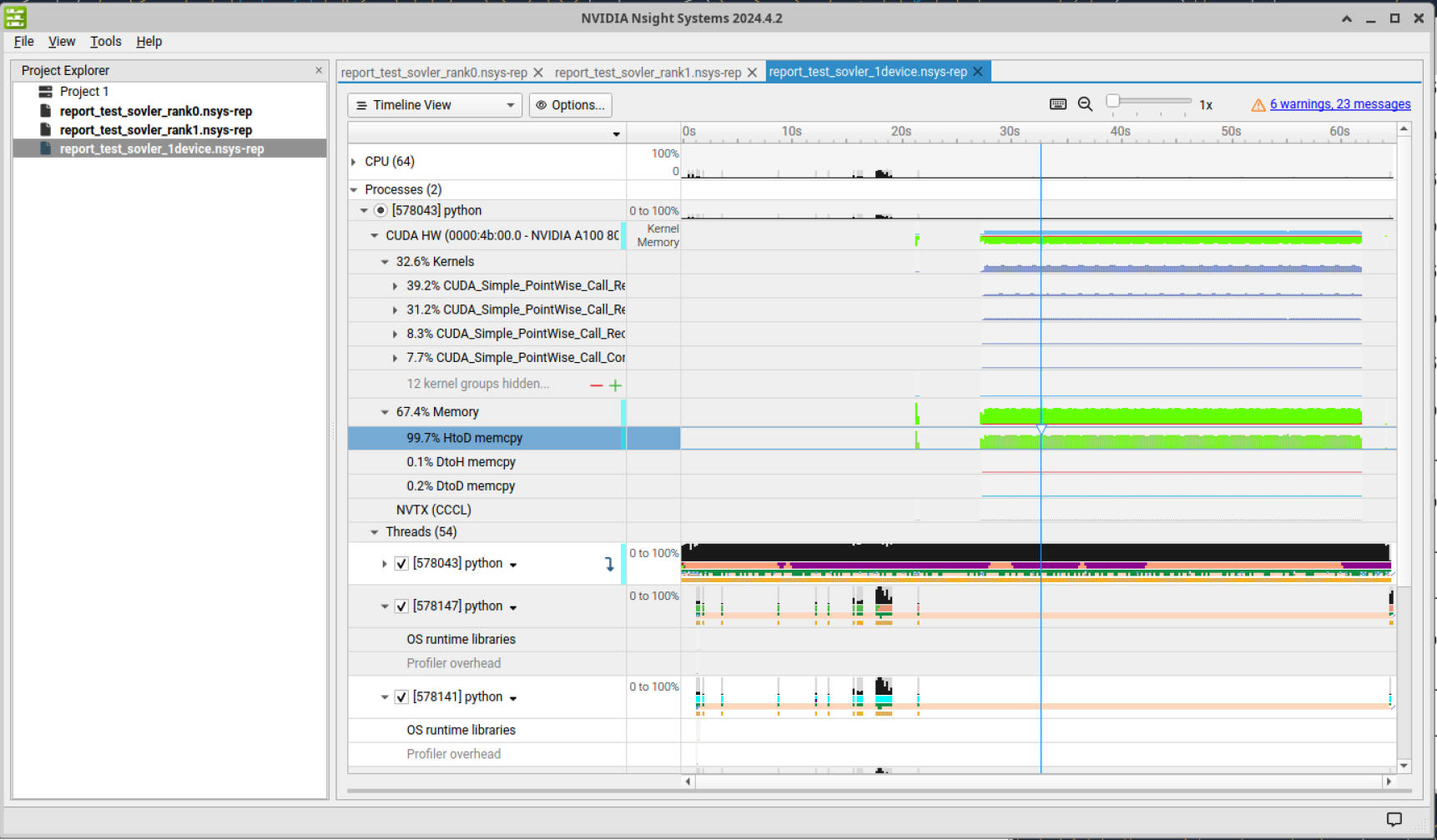
HUGE RX (host to device memcpy), 6-8GB/s why?
GPU occupancy (nvtop): ~60-70%!
Problem: unintended to_device() calls in initializing (rechecking) face buffer.
Fixing extra to_device
Fixed:
| Machine | Performance (CI/s) | Power estimated ( by software) (W) | Efficiency (MCI/kJ) |
|---|---|---|---|
| 1 A100 | 22.7M | 195 (GPU) + 165 (CPU Package) + 20 (RAM) = 380 | 59.7 MCI/kJ |
| 2 A100 | 39.8M | 180 (GPU) * 2 + 170 (CPU Package) + 20 (RAM) = 550 | 72.3 MCI/kJ |
| 32 CPU cores | 4.2M | 360 (CPU Package) + 45 (RAM) = 405 | 10.37 MCI/kJ |
GPU occupancy (nvtop): ~90%, RX/TX several MB/s
2 GPU v.s. 1 GPU: 88% strong scaling efficiency.
Optimized RecGradient and RecFace2nd
Primary optimization: local cache.
When only optimize RecGradient, consider the effect of using shared shuffle write or not:
Shared write (to 3x5 gradient) vs. direct write:
- total: 36.4MCI/s vs. 35.8MCI/s
- RecGradient: 2677 Iter, 8.79s vs/ 9.99s
Around 10% improvement.
Pitfall
If we use a buffer write function using __shared__ + __syncthreads() inside, you might want:
| |
To handle OOB threads. If write_data is templated or inlined, the __shared__ buffer could diverge.
Safe pattern:
| |
When both of RecGradient and RecFace2nd are optimized, performance:
| Machine | Performance (CI/s) | Power estimated ( by software) (W) | Efficiency (MCI/kJ) |
|---|---|---|---|
| 1 A100 | 58.1M | 237 (GPU) + 170 (CPU Package) + 21 (RAM) = 428 | 136 MCI/kJ |
| 2 A100 | 84.5M | 185 (GPU) * 2 + 175 (CPU Package) + 21 (RAM) = 566 | 149 MCI/kJ |
| 32 CPU cores | 4.2M | 360 (CPU Package) + 45 (RAM) = 405 | 10.37 MCI/kJ |
Occupancy: 86% 1 GPU / 71% 2 GPU
Write coalescing optimized
| Machine | Performance (CI/s) | Power estimated ( by software) (W) | Efficiency (MCI/kJ) |
|---|---|---|---|
| 1 A100 | 72.3M | 245 (GPU) + 170 (CPU Package) + 21 (RAM) = 436 | 166 MCI/kJ |
| 2 A100 | 98.2M | 195 (GPU) * 2 + 175 (CPU Package) + 21 (RAM) = 586 | 168 MCI/kJ |
| 32 CPU cores | 4.2M | 360 (CPU Package) + 45 (RAM) = 405 | 10.37 MCI/kJ |
| 64 CPU cores (AMD) | 10.9M | 384 (CPU Package) + 45? (RAM) = 429? | 25.41 MCI/kJ |
| 128 CPU cores (AMD) | 17.2M | 524 (CPU Package) + 45? (RAM) = 569? | 30.23 MCI/kJ |
| 256 CPU cores (AMD) | 19.6M | 570 (CPU Package) + 45? (RAM) = 615? | 31.87 MCI/kJ |
Occupancy: 83% 1 GPU / 66% 2 GPU
Larger case 256^3 (3D, more work per cell)
| Machine | Performance (CI/s) | Power estimated ( by software) (W) | Efficiency (MCI/kJ) |
|---|---|---|---|
| 1 A100 | 60.9M | 298 (GPU) + 170 (CPU Package) + 21 (RAM) = 489 | 124 MCI/kJ |
| 2 A100 | 78.1M | 230 (GPU) * 2 + 178 (CPU Package) + 22 (RAM) = 660 | 118 MCI/kJ |
| 32 CPU cores | 3.29M | 370 (GPU) (CPU Package) + 45 (RAM) = 415 | 7.93 MCI/kJ |
Occupancy: 99% 1 GPU / 90% 2 GPU